Table of content
Amazon Athena
Athena is out-of-the-box integrated with AWS Glue Data Catalog. Use-Cases:
- Ad-hoc Querying: Athena is ideal for running interactive ad-hoc queries on data stored in Amazon S3 without the need to set up and manage servers or data warehouses.
- Serverless Analysis: Since Athena is serverless, it’s well-suited for teams that prefer not to manage infrastructure and want to pay per query.
- Log and Unstructured Data Analysis: It’s commonly used for querying logs (e.g., ELB logs, CloudTrail logs), CSV, JSON, or other unstructured data formats directly in S3.
- Quick Insights: Athena helps when you need quick insights from data without the necessity of complex ETL processes.
When to Use Athena:
- When you need fast, serverless querying capabilities without the overhead of data warehouse management.
- For exploratory analysis and querying on data that’s already in S3, especially when data isn’t frequently accessed.
AWS Glue
Use-Cases:
- ETL Workflows: AWS Glue is a fully managed ETL service that prepares and transforms data for analytics. It’s designed to discover, prepare, and combine data for analytics, machine learning, and application development.
- Data Cataloging: Glue automatically discovers and catalogs metadata from your data stores into a central catalog that can be used for ETL jobs and queried by Athena and Redshift.
- Serverless Data Integration: It can automate the creation of ETL jobs, schedule and run them, and manage the dependencies between jobs.
When to Use Glue:
- When you have complex data processing and transformation needs before analysis.
- For orchestrating data ingestion, transformation, and preparation workflows in a serverless manner.
- To catalog data in S3 and other data stores for easier management, access, and analysis.
Glue crawler
Glue crawlers are automated data discovery tools that scan a data source to classify, group, and catalog the data within it automatically. It then creates new or updates existing tables in your AWS Glue Data Catalog.
Glue Data Catalog
The AWS Glue Data Catalog is an index of your data’s location, schema, and runtime metrics. You need this information to create and monitor your extract, transform, and load (ETL) jobs.
Amazon Redshift
Use-Cases:
- Data Warehousing: Redshift is a fully managed, petabyte-scale data warehouse service optimized for analyzing data using standard SQL and existing BI tools.
- Complex Queries and Analysis: Suitable for running complex queries and performing detailed analysis across large volumes of data.
- Real-time Operational Analytics: With Redshift, you can perform high-speed analysis on operational databases using Redshift Spectrum and federated queries.
- Data Integration and Sharing: Supports data integration from various sources and enables data sharing with other Redshift users.
When to Use Redshift:
- For enterprise-scale data warehousing and when you have large volumes of structured data requiring complex queries and analysis.
- When performance of analytics queries is critical and requires optimization through materialized views, distribution keys, and other data warehousing techniques.
- When there’s a need for integrating data from various sources and a consistent, high-performance database is required for BI and reporting tools.
EMR
Amazon EMR (Elastic Map Reduce) is hosted version of open-source tools Apache Hadoop, Apache Spark, HBase, Flink, Hudi, and Presto.
MapReduce is named after the two basic operations - reading data, putting it into a format suitable for analysis (map), and performing maths operations i.e. counting tax collected from houses (reduce).
const totalTax = data.results
.map(i => ({ n: i.houseNo, tax: i.houseTax })) // clean up data (chose)
.reduce((acc, i) => (!i.tax ? acc : acc + i.tax), 0); // maths operationWhen to Use EMR:
- Complex Analytics Workloads: Use EMR when dealing with complex analytical workloads that require the capabilities of Hadoop and associated tools like Spark for in-memory processing, machine learning, or SQL-based data exploration.
- Variable Processing Needs: EMR is a good choice when your data processing workload has significant variability, requiring you to scale resources up and down frequently.
- Customizable and Managed Hadoop Environment: Choose EMR when you need a customizable Hadoop environment but want to avoid the operational overhead of managing the cluster yourself.
EMR vs RedShift
| Feature | Amazon EMR | Amazon Redshift |
|---|---|---|
| Primary Use Case | Big data processing using frameworks like Hadoop, Spark. | Data warehousing and analytics. |
| Nodes | Cluster can be resized manually or automatically. | Cluster size can be adjusted, supports node types for different workloads. |
| Durability | Short Running (One Shot) | Long Running (24x7) |
| Security | Encryption in transit/at rest, IAM roles, network configurations for security. | Offers encryption, VPC, IAM roles, and also supports Redshift Spectrum for secure data querying. |
| In VPC | Can be launched within a VPC for isolated processing. | Runs in VPC by default for enhanced network security. |
| Backup | Depends on the data storage used (e.g., S3). Manual snapshot management for HDFS. | Automated and manual snapshots to S3, with configurable retention periods. |
| Cost | _ Pricing based on the type and # of instances, and the duration of cluster operation. _ Spot-Instance for low cost | Pricing based on node types, # of nodes, and hours run; also offers reserved instances for cost saving. In general expensive |
| Data Sources | S3, DynamoDB, HDFS. | S3, Dynamo, RDS, EMR, Glue, EC2 |
| Data Destination | S3, HDFS, or exported to other systems. | Results are typically stored within Redshift clusters but can be exported to S3 or other services. |
| Performance | Performance depends on the chosen hardware and software configuration. Optimized for parallel processing of big data. | Highly optimized for complex queries across large datasets using columnar storage and data compression. |
| Scalability | Highly scalable, supports adding/removing instances to the cluster as needed. | Scalable, with the ability to resize clusters and use elastic resize for quick adjustments. |
| Management | Managed Hadoop framework, but requires configuration and management of applications. | Fully managed service, with less operational overhead for scaling and maintenance. |
Summary of Athena, Glue, RS and EMR
- Use Athena for serverless, ad-hoc querying on data stored in S3 without the need for a complex ETL process or when you want a simple way to query data for quick insights.
- Use Glue for data preparation, ETL processes, and data cataloging when dealing with complex transformations and integrations between various data sources and services.
- Use Redshift for comprehensive data warehousing solutions that require high performance, complex queries, and deep analytics on structured data across large datasets.
- EMR is a versatile, scalable solution for processing and analyzing large datasets, especially when leveraging the Hadoop ecosystem’s tools. It’s designed to efficiently handle everything from batch and stream processing to complex analytics and machine learning, providing a managed platform that reduces the operational burden of big data processing.
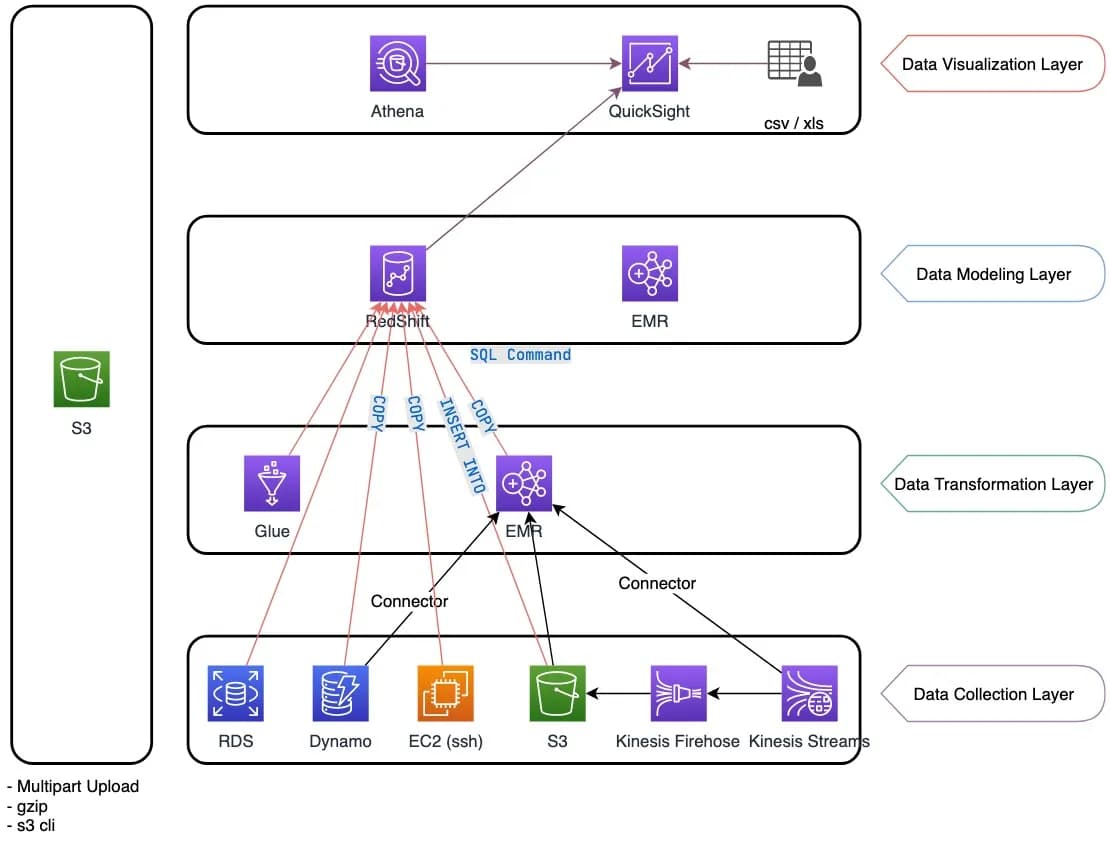
Complex Use-Cases
There are several use cases where combining AWS Glue, Amazon Athena, Amazon Redshift, and Amazon EMR could be beneficial to achieve complex data processing, storage, and analysis objectives. These AWS services complement each other and can be used together in various data engineering and analytics workflows.